This page is on Eidetic Design - what it is (according to our understanding up to 2010), examples and software for download.
It is an accompanying page for a paper as well as a pool of ressources for this exciting topic.
Enjoy the tools below and feel free to email me and Matthew
for questions.
WebVoice: examples and clients (user interfaces) for immediate interactive use from within the browser are available when following the link. The original code is written in C++, so other bindings than the web service are available on request.
WebVoice alternative link (recommended): be patient when clicking "work", there is no indicator of process, but after few minutes (at max!), a download button will appear (with a non-working process indicator ;-). Save the file with the extension ".wav" and listen to it with your favourite audio player.
The Adaboost model trainer and visualizer is based on Java code; a preliminary version may be requested.
A tutorial video of how WebVoice may be used can be found here and below:
Examples
Speaker Clustering: speaker clustering (or diarization) is a research topic since the early 1990's, but its error rates are still
order(s) of magnitude above those of the relatively easier task of speaker identification (on datasets that are even an order of magnitude
smaller), and far away from what humans can achieve. Why is this so? Is there crucial (human-exploitable) information missing in the
features (typically MFCC) or models (most often GMM)? What might this information be?
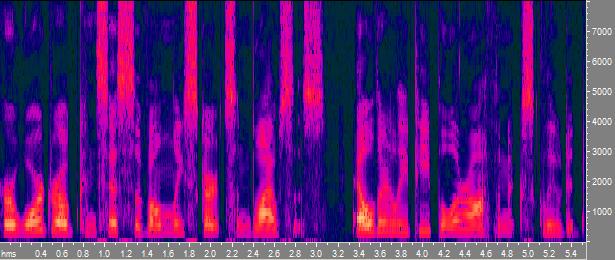
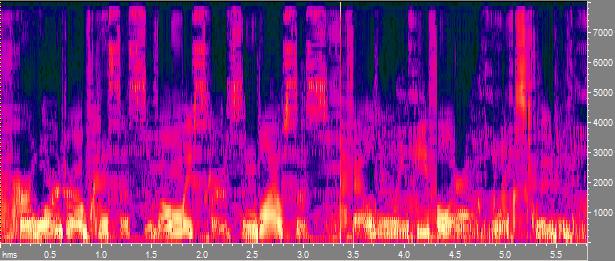
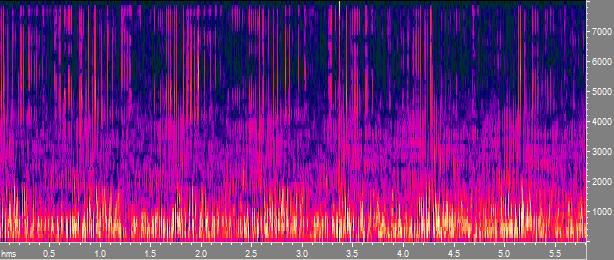
The three pictures show spectrograms of two concatenated sentences from the TIMIT corpus, their resynthesized MFCC features and their
resynthesized GMM statistical speaker model (built from the aforementioned MFCCs), repsectively. A click on each spectrogram reveals the
corresponding sound file. Starting from the first file, the other two files can be generated using
WebVoice using standard parametrization of the respective methods.
For an automatic speaker clustering system there is no difference in the quality of the three files - i.e., it doesn't use more
information than is conveyed by the resynthesized GMM. But humans, being able to correctly group speakers together on resynthesized MFCC
files, crucially miss time coherence information here. This result and a corresponding
solution could be achieved by observing algorithmic behaviour of a speaker clustering system in an eidetic way.
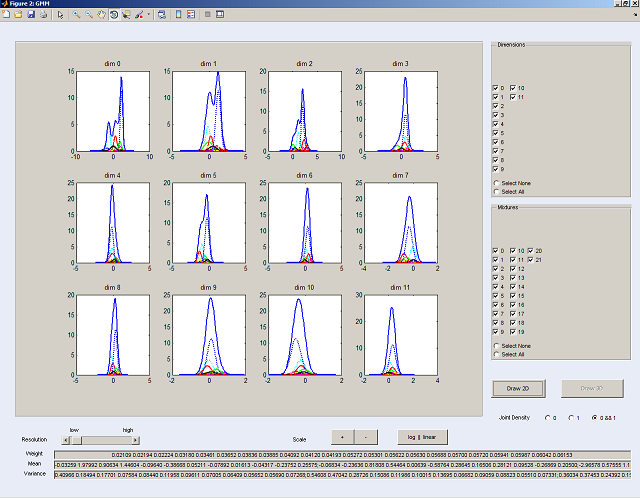
Speaker Identification: The standard model in speaker recognition is the multimodal diagonal-covariance Gaussian Mixture Model,
trained via the EM algorithm. But how can we be sure that the parameters have been estimated "reasonably"? A plotting tool like
PlotGMM might help (in contrast to resynthesis as in the previous example, that helps when assessing the content of the model rather than the parameters):
We see here the display of the 12 dimensions (MFCC) and 22 mixtures of a speaker model, conditioned on 52.5 seconds of German news anchor
speech (the sound file may be accessed by clicking on the image). What comes to the eye is that while the first dimensions seem to be truly multimodal or skewed, e.g. dimensions 9-11 seem to be
quite single-Gaussian distributed. We could save free parameters of the model (that has a diagonal covariance anyway) by estimating for
each dimension separately the optimal mixture count! Getting right with less parameters means that we need less data to estimate the
statstics, so such a dimension-decoupled GMM might be a better choice when it comes to modeling short utterances.
These are the plots of speaker identification accuracy versus data size using 3 different GMM variants in an experimental setup equal to
the one created by Reynolds. The horizontal axis shows how
many percent of the data originally used by Reynolds have been removed; the blue line stands for the dimension-decoupled (DD) GMM, the
green line for Reynold's standard GMM with 32 multimodal mixtures (32-GMM) and the red line for such a standard GMM with a optimized
number of mixtures for each speaker via the BIC (BIC-GMM). It is quite obvious that the dimension-decoupled GMM helps when it comes to
small samples sizes, and this result could be achieved using an eidetic plotting tool.
Some publications regarding our tools and respective results:
Other works not by us nor related to us directly, but accomplished in a mindset that we deem to be eidetic; or tools that can be
useful in eidetic design:
MusicalAlgorithms: an algorithmic process is used in a creative context so that
users can convert sequences of numbers into sounds. A german tech magazine describes it as follows: "Mit einer guten Visualiserung erkennt
das menschliche Auge Zusammenhänge, die ihm anhand der bloßen Zahlenkolonnen verborgen geblieben wären. Warum nicht zur Abwechslung
mal die Ohren benutzen?" (c't 23/2009, p. 198).
...
Short introduction (please read the full paper for a better overview, also graphically): Contemporary speech processing systems are complex, typically
consisting of several algorithms often containing sub-algorithms, with numerous processing steps whose effects and parameter settings are
not intuitively understandable by humans. This leads to several problems when designing new and adapting or replicating existing algorithms.
Taking the mel frequency cepstral coefficients (MFCC) algorithm for speech features as a concrete example, parameters such as the number of
coefficients to keep are relatively easy to understand, but other parameters, such as the window type or the size of the filter bank, are
more abstract, making it difficult to intuitively judge their importance and their effects on the whole processing chain. When designing a
new algorithm based on theoretical results, adapting an existing algorithm to a new environment or reimplementing a published algorithmic
description for comparison, there is usually no instant success due to such misconceptions. When the results do not meet the expectations,
several questions arise: What effect does a change of a parameter in a component of an algorithm have? What does the selection of a particular
algorithmic technique in the presence of several possibilities have on the overall functionality of the system? What is the contribution
of a specific algorithmic step?
In our research, we found several examples where we've been able to find the solution to such questions (and subsequent algorithmic novelties)
by a specific method of design. Reviewing the factors that lead to success in these examples, we've bundled the main principles that we have
found effective in approaching algorithm development, and that we believe have long been underestimated in speech processing. We call this
approach Eidetic Design because it is based on using our
natural senses to analyze speech algorithms and discover whether a problem with an algorithm stems from the underlying theory or is a
configuration or implementation issue. This novel approach to algorithm design also enables algorithm improvement to be approached in an
intuitive way and makes teaching algorithms significantly more understandable.
What makes design eidetic? The process has to be characterized by the following key principles: it starts with an existing algorithm and is
aimed at getting insights into a specific algorithmic step for a specific reason; the reason and the algorithmic step (represented by its
intermediate result) form the problem. Both the question (aspect of interest in the data) and the data (intermediate algorithmic results)
determine a suitable domain to cast the data to. In our experience, the most suitable domain to cast data to (e.g. to an audible or visual
representation) is often the one that corresponds naturally to human imagination of this data under a certain question. We then...
design a human-in-the-loop approach for introspection;
apply tools that provide comprehension by...
making data perceivable in the most suitable domain...
consistent with the natural use of human senses;
in areas where the human brain is considered an expert in answering this question for this data.
Eidetic Design relies on the problems to have such a natural mental representation, and on tools to be available that generate the vivid
"experience" of the inner workings of algorithms. These tools can not be completely generic, but need to be developed for the specific
problems at hand.
Thus, Eidetic Design has something in common with traditional visualization techniques, but is more.